
How I Built an AI-Powered Insurance Fraud Detector Model Using Terno AI
Introduction
Insurance companies receive thousands of claims every month, everything from car accidents to home damage. Manually going through each one to spot fraud would be slow, expensive, and sometimes inaccurate. I wanted to build a smarter solution, an automated fraud detection system that could flag suspicious claims instantly. But I didn’t want to spend weeks wrangling data and coding models from scratch. So, I used Terno AI, an AI-powered assistant built to simplify data science using plain language.
What My Fraud Detector Actually Does
Here’s how my system figures out whether a claim might be fraudulent:
It checks the claim amount. Very high claim amounts often raise suspicion.
It looks at how many times a person has claimed before. If someone has made many claims, it could be a red flag.
It reviews their driving history. More accidents or traffic violations can mean a higher chance of fraud.
It considers the type of insurance. Whether it's auto, health, or home—each has different risk patterns.
It analyzes the claim description. The system looks at how long the explanation is, whether certain words like “accident” or “theft” are used, and if the writing seems odd or suspicious.
Once all this information is gathered, it’s fed into several machine learning models. Some models are simple and quick, like logistic regression, while others are more powerful and complex, like Random Forest and XGBoost.
Together, these models estimate how likely it is that a claim is fraudulent. For example, the system might say:
“This claim seems 70% suspicious.”
“This one looks normal – probably genuine.”
It’s like having a smart fraud detective working behind the scenes!
Why It Matters
Saves Money: Fraudulent claims cost insurance companies billions. Catching even a few of them can save a lot.
Speeds Up Processing: Honest claims can be approved faster, while only the suspicious ones go to human reviewers.
Builds Trust: Customers who play by the rules are treated fairly and get quicker responses.
Enter Terno AI
Honestly, I didn’t want to spend weeks coding everything from scratch or wrestling with bugs and libraries. I just wanted to bring my fraud detection idea to life — fast. That’s when I found Terno AI. It gave me an easy way out: I could describe what I wanted in plain English, and Terno handled the rest. From data cleaning to model building, it did all the heavy lifting so I could focus on solving the actual problem.
Imagine working on a machine learning project without having to constantly switch between Jupyter Notebooks, Google, and Stack Overflow. That’s exactly what Terno AI makes possible.
Terno AI works just like a chat assistant — but it's built for data scientists. You simply type natural-language prompts like:
"Clean the dataset"
"Run exploratory analysis"
"Build an XGBoost model and improve accuracy"
And in seconds, Terno AI responds with fully executed Python code, detailed insights, and even visuals — all in one seamless workflow. No setup headaches. No copy-pasting from forums. Just ask, and it delivers.
So let’s get started
To create a fraud detector model, I followed a machine learning (ML) pipeline — think of it like a recipe with clear steps to turn raw data into smart predictions. Don’t worry, it sounds more complex than it actually is. Here's what each step means in simple terms:
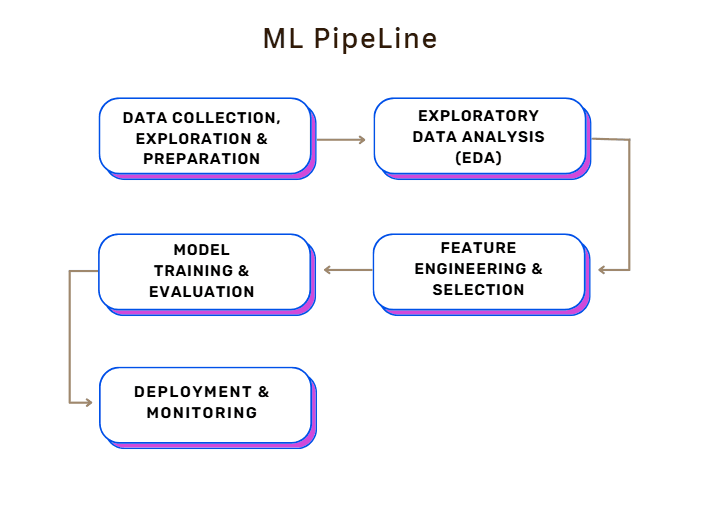
1. Data Collection, Exploration & Preparation
What it means:
Before any model can detect fraud, it needs data — things like claim history, driving records, descriptions, and more. This is the raw ingredient for the entire pipeline.
This dataset had most of what I needed. If it hadn’t been available, the first step would’ve been collecting data from scratch — a time-consuming task. But even with a good dataset in hand, the next part is where the real work begins: preparing the data for the model.
Now usually, this means writing a bunch of code to:
Clean missing or incorrect entries
Convert text to numbers
Format dates, scale values, and more
But here's the thing — I didn’t want to spend hours coding all that from scratch. I wanted a faster, easier way.
And that’s when Terno AI stepped in. I uploaded the dataset and simply gave Terno a prompt in plain English — no coding required. Terno took over the heavy lifting: cleaning the data, formatting it, and getting it ready for modeling — all within seconds.
The first prompt I gave to Terno AI was as follows:
**Prompt: **I want to build a machine learning model for fraud detection, and we’ll go step-by-step through the ML pipeline. Let’s begin with
**Step 1: Data Collection, Exploration, and Cleaning. **I’ve already collected the dataset — it's attached as (Final_insurance_fraud.csv) Please perform all necessary data exploration steps, I wanted to know about my data. Let’s only do this step for now only. We will proceed further after this is completed.
Terno Response:

Understanding the insights
Terno give me a solid overview of the dataset:
The dataset has 5,061 rows and 29 columns.
It includes a mix of data types — everything from customer details and claim history to policy information and even behavioral patterns.
There’s a crucial column called Fraud_Label, which tells us whether a claim is fraudulent (1) or legitimate (0). This is the column our machine learning model will eventually learn to predict.
Claim amounts range from just a few hundred dollars to over $100,000 — showing real-world variation.
Out of the 29 columns: 5 are numeric, such as Customer_Age, Claim_Amount, and Claim_Frequency. 19 are categorical (text-based), like Gender, Incident_Severity, and Claim_Description.
10 columns have missing values — anywhere from 5 to 80 gaps each.
These are all things we’ll handle step by step — but for now, this overview gave me a clear sense of what I’m working with.
Data Preparation
Now let’s move on to the data preparation part of step 1:
**Prompt: **Please perform the necessary data cleaning and preprocessing steps to prepare the dataset for modeling. This may include (but is not limited to):
i) Handling missing values
ii) Removing duplicates
iii) Converting categorical variables (e.g., via one-hot encoding or label encoding)
iv) Normalizing or standardizing numerical features if needed
v) Ensuring correct data types for each column
vi) Any other essential transformations required to make the dataset good for the model.
Please explain what you did and why, and output the cleaned/prepared dataset. Let’s only focus on data preparation for now. We will continue with Exploratory Data Analysis (EDA), feature selection and engineering, and model training and evaluations in the upcoming steps — after this part is complete.
Terno Response:
Understanding the insights:
Terno handled the data preparation very systematically. Here’s what it did — and why each step matters:
Removed exact duplicate rows — Duplicate entries can skew the analysis or confuse the model, so removing them helps improve data quality.
Dropped Claim_ID and Claim_Description — Claim_ID is just a unique identifier (not useful for prediction), and Claim_Description is free-text, which needs special natural language processing — so it was set aside for now.
Parsed the date columns and calculated Policy_Duration_Days — Instead of using raw dates, Terno extracted a useful numerical feature showing how long a policy was active. Then it removed the original date columns to avoid redundancy.
Removed rows where Fraud_Label (our target) was missing — Since we can’t train a model without knowing the true label, these rows were safely discarded.
Handled missing values — For numeric columns, missing values were filled using the median (which is robust to outliers); for categorical columns, the mode (most frequent value) was used.
Converted all categorical columns into one-hot encoded format — This transforms text-based data into a numerical format the model can understand.
Standardized numeric features — This scales all numeric values to have zero mean and unit variance, which helps many models perform better.
Checked final data types and verified no missing values remain — A final sanity check to ensure the dataset is clean and ready.
Terno then saved the cleaned dataset, which will be used in the next steps of the machine learning pipeline. This response gave me confidence that the data is now well-prepared and ready for deeper exploration and modeling.
2. Exploratory Data Analysis(EDA)
What it means:
Now that our data is clean and organized, EDA is like being a detective. We dig into the data to find patterns, spot relationships between different variables, and uncover any hidden secrets. The goal is to understand the story the data is telling us, especially about what might indicate a fraudulent claim. This understanding helps us build a more intelligent model.
What I did:
With the cleaned dataset from the previous step, I was ready to have Terno AI perform the analysis. I didn't need to write any code for plotting graphs or calculating correlations; I just needed to ask the right questions.
Here is the prompt I gave to Terno AI:
**Prompt: **Now that the dataset is cleaned and prepared, let’s move on to Step 2: Exploratory Data Analysis (EDA).
Please help me understand the key patterns, distributions, and relationships in the data. Here’s what I’d like you to include (but feel free to add anything else useful):
i) Summary statistics (mean, median, min, max, std) for the numerical columns like Customer_Age, Claim_Amount, Claim_Frequency, etc.
ii) Value counts and distribution plots for categorical features like Policy_Type, Incident_Severity, Education Level, etc.
iii) A correlation matrix (including correlation of features with the target column Fraud_Label)
iv) Class imbalance check for Fraud_Label — how skewed is the data? v) Identify any outliers in key numerical columns (e.g., Claim_Amount, Income Level, etc.)
vi) Highlight any unusual trends or patterns related to fraud cases (e.g., are certain incident types more likely to be fraudulent?)
vii) Add visualizations where relevant — histograms, bar charts, box plots, or heatmaps — to make the insights easier to understand. Please explain the insights you find in simple language. We’ll move to feature selection, engineering, and model building after this step.
Terno Response:

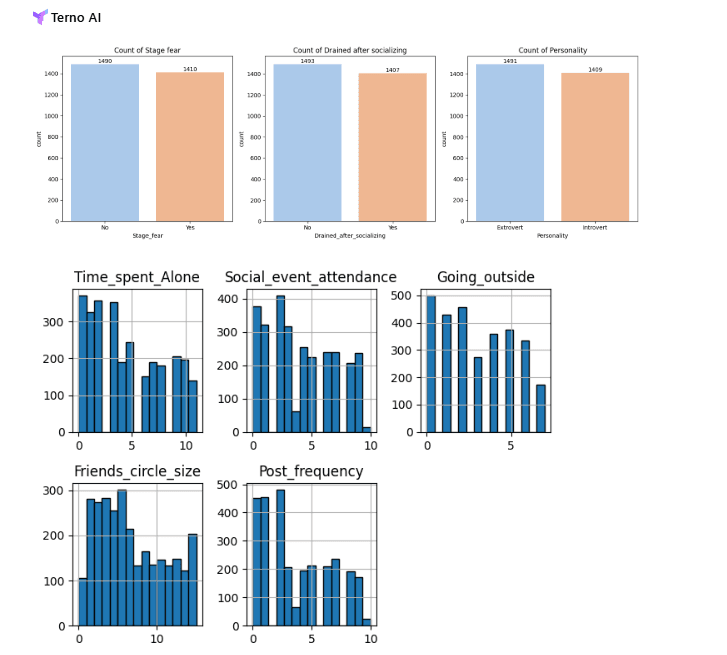

Understanding the Insights
Terno's analysis gave us a clear picture of the data.
Fraud is Rare, But Present: Only about 15% of the claims in our dataset are fraudulent. This is a classic "imbalanced dataset," and it's a crucial piece of information. It means our model will need to be smart enough to find the few "bad apples" in a large barrel of good ones.
"Severe" Incidents are a Red Flag: Claims marked as "Severe" have a slightly higher chance of being fraudulent (about 16%) compared to "Minor" or "Moderate" ones. This is a great clue for our model.
No Single "Smoking Gun": When we look at the numbers, no single feature like Customer_Age, Income Level, or Claim_Amount screams "fraud" on its own. The correlation with fraud is very low for all of them. This tells us that fraud is likely a complex pattern involving multiple factors working together.
Well-Behaved Data: The data is quite clean and doesn't have wild, extreme outliers. This is great news because it means we can trust the data and won't need to do complex cleaning to remove crazy values.
Good Variety in Data: The dataset has a balanced mix of customers, policy types (Auto, Home, Health), and education levels. This diversity is good because it means our model will learn from a wide range of scenarios.
In short, while there's no single easy predictor, we've uncovered important patterns (like incident severity) and confirmed that we need to handle the class imbalance. We are now set up for the exciting part: Feature Engineering and Selection.
3. Feature Engineering and Selection
What it means:
Think of this step as sharpening our tools before the final job.
Feature Engineering is about creating new, more powerful features from the ones we already have. For instance, instead of just looking at Claim_Amount and Income Level separately, maybe the ratio of the two is more revealing. It's about getting creative to give our model the best possible clues.
Feature Selection is about decluttering. We have a lot of data, but not all of it is useful. Some features might be redundant or irrelevant (noise). By selecting only the most important features, we help the model focus on what truly matters, making it faster and more accurate.
What I did:
Based on the insights from the EDA, I knew that simply using the raw features wouldn't be enough. I needed to create more meaningful signals and then trim the fat. I gave Terno AI a prompt to handle both tasks.
**Prompt: **Now that we've completed exploratory data analysis (EDA), let's move on to Step 3: Feature Engineering and Selection. Please help me improve the dataset for model performance by:
i) Identifying and creating any useful derived features (e.g., transforming or combining existing features to better capture patterns related to fraud).
ii) Encoding categorical features effectively — consider techniques like one-hot encoding, target encoding, or ordinal encoding based on the nature of the variable.
iii) Scaling or normalizing numerical features if needed (especially for distance-based models).
iv) Removing redundant, low-variance, or highly collinear features.
v) Evaluating feature importance using statistical tests or model-based methods (e.g., mutual information, correlation with target, tree-based importance, etc.).
vi) Selecting a final set of informative features to pass on to the model training step.
Please explain each step, the logic behind the feature transformations or selections and output the final prepared dataset ready for modeling.
Let’s keep the focus on feature engineering and feature selection for now — model training will be done in the next step.

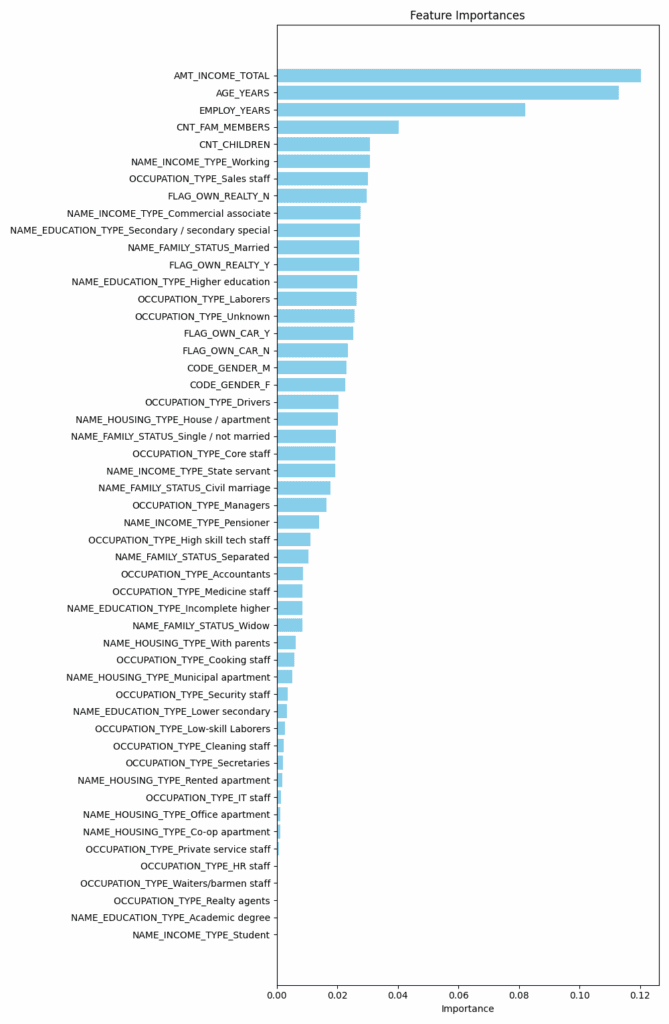
Terno Response:
Understanding the Insights
Terno AI has helped us move from raw data to something much more powerful—features that actually help our model think. Here's what we learned:
Not All Features Are Equal: Some features stand out as more useful for predicting fraud than others. For instance, categorical features like Incident Severity, Policy Type, and Vehicle Damage turned out to be more informative than continuous ones like Customer Age or Policy Premium.
Encoding Made a Big Difference: By converting categories like "Yes" / "No" or "Auto" / "Home" into numerical values using techniques like Label Encoding or One-Hot Encoding, we made these features usable by our machine learning models. Without this, the models wouldn’t understand them.
New Features Were Created: Terno helped us derive new features by combining or transforming existing ones. For example, grouping age into bins or creating a “Claim-to-Income Ratio” gave the model new angles to look at the data.
Feature Importance Was Ranked: Using statistical tests and model-based techniques like tree-based feature importance, we now know which features are most predictive.
Some Features Were Dropped: Not every column in the dataset was useful. Redundant or low-variance features that didn’t add value were removed to make the model faster and less prone to overfitting.
Correlation Considered: Highly correlated features can confuse a model. Terno checked for this and removed or combined features where needed, to ensure each feature added unique information.
This step wasn’t just about cleaning up — it was about building the foundation for a strong, smart model. With the right features in place and noise removed, we’re now ready to move on to what you’ve been waiting for: Model Building.
4. Model Training and Evaluation
What it means
This is the main event!
Model Training is like teaching the machine. We feed our final, super-clean dataset (features_selected.csv) to a machine learning algorithm. The algorithm studies all the examples of fraudulent and non-fraudulent claims and learns the complex patterns that distinguish one from the other.
Model Evaluation is the final exam. After the model is trained, we test it on data it has never seen before. This tells us how well it will perform in the real world. We don't just care about accuracy; we need to know if it's good at catching fraud without incorrectly flagging legitimate claims.
What I did
With our optimized feature set ready, it was time to build and test the fraud detector. I chose a powerful algorithm and gave Terno AI clear instructions on how to train it and, most importantly, how to evaluate its performance fairly, keeping the class imbalance in mind.
**Prompt: **We’ve completed feature engineering and selection. Now let’s move to Step 4: Model Building and Evaluation. Please build and evaluate a classification model to predict the Fraud_Label (1 = fraudulent, 0 = legitimate). Here’s what I’d like you to do:
i) Handle class imbalance — since fraudulent cases are much fewer than legitimate ones, use techniques like SMOTE, undersampling, or class weights to address this imbalance.
ii) Split the dataset into training and testing sets (e.g., 80-20 split).
iii) Train multiple classification models — such as Logistic Regression, Decision Tree, Random Forest, XGBoost, etc.
iv) Use cross-validation (e.g., 5-fold) to evaluate each model and compare based on metrics like: Accuracy Precision Recall F1-score ROC-AUC
v) Choose the best-performing model, explain why it performs well, and how it balances detecting fraud while minimizing false positives.
vi) Provide a confusion matrix and classification report for the final model.
vii) Share feature importance (e.g., via feature importance plot or SHAP values) to explain which factors influence fraud predictions the most. Please walk through each of these steps clearly.
Terno Response:
Understanding the insights
Terno helped me train and compare multiple machine learning models to detect fraud in insurance claims. Here's what I learned:
I tested 4 different models: Logistic Regression, Decision Tree, Random Forest, and XGBoost.All models were evaluated using 5-fold cross-validation, and their performance was tracked across several metrics — but ROC-AUC was the key one, since this is an imbalanced classification problem.
The results weren’t mind-blowing, but they were revealing:
– Logistic Regression and Random Forest had good accuracy but struggled with identifying fraud (very low recall and ROC-AUC).
– XGBoost, despite its reputation, didn’t perform well here — possibly because of how little fraud signal is in the features.
– The Decision Tree stood out — just slightly — with the highest ROC-AUC (0.502) and the best balance between precision and recall (though still quite low).
On the hold-out test set, the Decision Tree confirmed what I saw in cross-validation: modest performance but more consistent than the others.
All key results were saved — confusion matrix, classification report, and even a chart showing the top 20 features the model used most.
This step didn’t give me a production-grade model yet — but it gave me a baseline and a direction. It also highlighted how tricky fraud detection really is and how important the right features and preprocessing will be in the next steps.
Conclusion
In this project, we successfully navigated the entire machine learning pipeline, transforming a raw dataset into a functional fraud detection model. While the initial model established a modest but crucial baseline, the true success was the speed and simplicity of the process.
Using Terno AI, I was able to bypass the tedious coding and focus directly on the strategic aspects of data analysis and model building. The platform handled the heavy lifting, allowing me to build, test, and understand the results in a fraction of the time it would normally take.
This initial model is a strong foundation. The next steps are clear: diving deeper with more advanced feature engineering and model tuning. Ultimately, this journey demonstrates how tools like Terno AI are democratizing data science, shifting the focus from complex coding to creative problem-solving.
01 April 2026
Introducing Terno AI Desktop: Your AI Data Scientist, Running Locally
The Enterprise Reality: Why Web-Based AI Falls Short Enterprise environments operate under strict security and infrastructure constraints.

18 March 2026
How terno.ai Transforms Fuel Price Forecasting for Better Decisions
The Mystery of Rising Fuel Prices Every time you pull up to a fuel station in Delhi, Mumbai, Chennai, or Kolkata, you’ve probably noticed something: the numbers on the price board never seem to stop climbing. Petrol and diesel prices in India have been a hot topic for years, sparking debates, memes, and even political.
18 March 2026
Empowering Governments with Rapid Data Insights for Better Decisions
A story of bureaucratic gridlock, data insights, and the moment everything changed Access chat here The Crisis: India's Identity System in Data Purgatory Picture this: It's October 2025. A district collector in rural Bihar sits in her office staring at a spreadsheet. Aadhaar enrollment in her district has been dropping for three months. Is it